Specificity and Abstraction in Software Engineering
By Andrew Rousseau. Published on April 5, 2023.
The battle against complexity in software engineering is constant and at every level from systems to applications and down to modules and methods. Things start simple and complexity grows through the choices we make. It isn't always apparent as we make those decisions but over time complexity will grow at every level if we aren’t vigilant.
We must walk a narrow path to find a balance that results in the least complex solution and one that improves readability and maintainability. Complexity is determined by the types and levels of abstraction as well as how specific and generic the abstractions and overall code is. Let’s first dive into some of these terms more deeply.
The purpose of an abstraction is to hide the implementation details of a given solution. If done correctly this should result in more readable code as it shifts the details out of one context and into another. One need not concern themselves with those details unless they are addressing a change or defect within the abstracted context.
Abstraction is one of the fundamental concepts of software engineering and is evident in most codebases we encounter. Most applications an engineer will work on these days consists first as a collection of dependencies that are required for the execution of the application's specific code. This could be in the form of libraries or even a framework which our codebase will leverage. These provide a set of high-level interfaces we can utilize without worrying about the details of the implementation.
Abstractions are used in both object-oriented and functional programming. An object or struct should have a clearly defined interface that communicates things like its attributes and their types as well as its functionality. This should be done in a way that doesn’t require the engineer to look too deeply into the details to implement it.
While abstraction is a powerful tool that can be used to simplify complexity it has to be handled with care so that we don’t inadvertently increase the dynamic complexity to the extent that the engineer must constantly shift context from one abstraction to another to follow the logic in a given solution. The abstraction must only hide the details that aren’t required to understand the code and it must articulate the uses clearly enough to be understandable without needing to investigate those details.
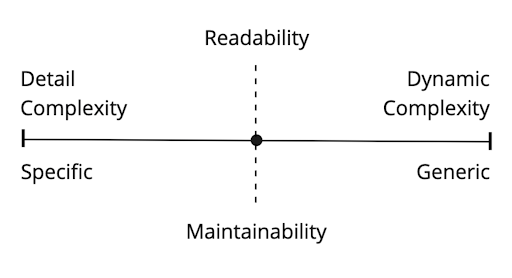
Specificity in software engineering is the degree to which the code is designed for a specific or generic use. Highly specific code often results in high detail complexity and highly generic code can result in high dynamic complexity.
How specific or generic a solution is depends upon how fixed or variable its parts are. The more fixed they are the more specific the solution is and the more variable they are the more generic it is. A method with a high level of parameterization for instance would be highly variable and therefore more generic. The variability also results in a higher level of dynamic complexity.
For the most part, tending toward either extreme here is not desirable if we value readability and maintainability. We have to find the balance between these by vigilantly weighing the tradeoffs of one versus the other. We must also be willing over time to rewrite code that has become unnecessarily complex.
While abstractions are a good tool in our toolbox, we often reach for it too early and often. Code that has been abstracted is often done so in a generic way which increases dynamic complexity. If you only have a single use case for an abstraction it may not make sense as the code is not ready yet for reuse.
We will be tempted with the second use case to create a generic abstraction. However, two use cases are not likely enough to understand the full requirements for a truly generic implementation and may result in the need for conditional logic to be added for later uses. This somewhat negates the benefit of hiding those details as the engineer must switch context to follow the branching logic in the abstraction.
Instead, we should wait for the third use case before creating the abstraction to ensure that we have determined a relatively generic implementation. We must also be willing to undo the abstraction if it reaches a third conditional branch of logic as it now is the wrong abstraction. While it may feel wrong to have some repetition of logic in our codebase, holding off on abstractions to ensure we define them well will save us the burden of context switching resulting from dynamic complexity.
Writing code with readability and maintainability in mind requires us to walk the razor's edge between specificity and abstraction. Both are viable when implemented in a way that is easy to understand and won't require a high level of context switching. We must be willing to weigh trade-offs instead of adhering strictly to industry conventions and norms as they can sometimes inadvertently increase complexity. We must be slow to abstract and quick to dismantle wrong abstractions, which is the opposite of most engineers' inclination. If we can do that, then we improve our chances of writing readable and maintainable code.